
Hi there! I’m Gokul, a recent PhD graduate from Carnegie Mellon University’s Robotics Institute, working on the algorithmic foundations and science of interactive decision-making.
I work on efficient interactive learning algorithms for training agents (e.g., robots, language models). More fundamentally, I am interested in techniques for learning to make good decisions efficiently, even when “good” is hard to specify. I value closing the theory-practice loop: my research proceeds in cycles of deeply understanding empirical phenomena, making algorithmic advancements, and deploying my ideas broadly.
I recently completed my PhD at CMU, where I worked with Drew Bagnell and Steven Wu. I completed my B.S. / M.S. at UC Berkeley, where I worked with Anca Dragan. I’ve spent summers working on ML @ SpaceX, Perception @ NVIDIA, Motion Planning @ Aurora, World Models @ Microsoft and LLMs @ Google.
🌟 I am currently on the job market! 🌟
Events & News
April 2026 - I passed my thesis defense and am now officially a doctor! I couldn’t have done it without the support of my advisors, labmates, friends, and family – thank you all!
February 2026 - Two new papers out on learning from noisy LLM judge feedback: SP3F provides LLM judges with privileged information for better feedback on low-resource language reasoning problems, PROSPER robustly learns from rubric-based LLM Judges via ideas from Blackwell Approachability.
January 2026 - Particularly exciting paper accepted to ICLR 2026 on the real value of RL in fine-tuning / RLHF. I gave a talk at Cornell on the paper that might also be of interest.
November 2025 - I’m incredibly grateful to be named a Rising Star in Data Science and Robotics and recieve the inaugural CMU RI Outstanding Graduate Teaching Assistant Award!
June 2025 - Two new papers out on learning to search: SAILOR that outperforms diffusion policies trained on 10x as many demos on multi-stage visual manipulation tasks (Spotlight @ NeurIPS ‘25), FOREWARN that allows real robots to avoid semantic failures via VLM verifiers (RSS ‘25, Outstanding Paper at ICML ‘25 Workshop).
November 2024 - Drew, Steven, and I are co-teaching a course on the algorithmic foundations of interactive learning. If you’d like to understand the fundamental principles behind imitation (e.g. for robots) and RLHF (e.g. for LLMs), this is the course for you!
Research Highlights
A Smooth Sea Never Made a Skilled 𝚂𝙰𝙸𝙻𝙾𝚁: Robust Imitation via Learning to Search

We introduce 𝚂𝙰𝙸𝙻𝙾𝚁: a method for learning to search from expert demonstrations that out-performs Diffusion Policies trained in 5-10x as much data on multi-stage visual manipulation tasks. [Site] [Paper] [Podcast]
All Roads Lead to Likelihood
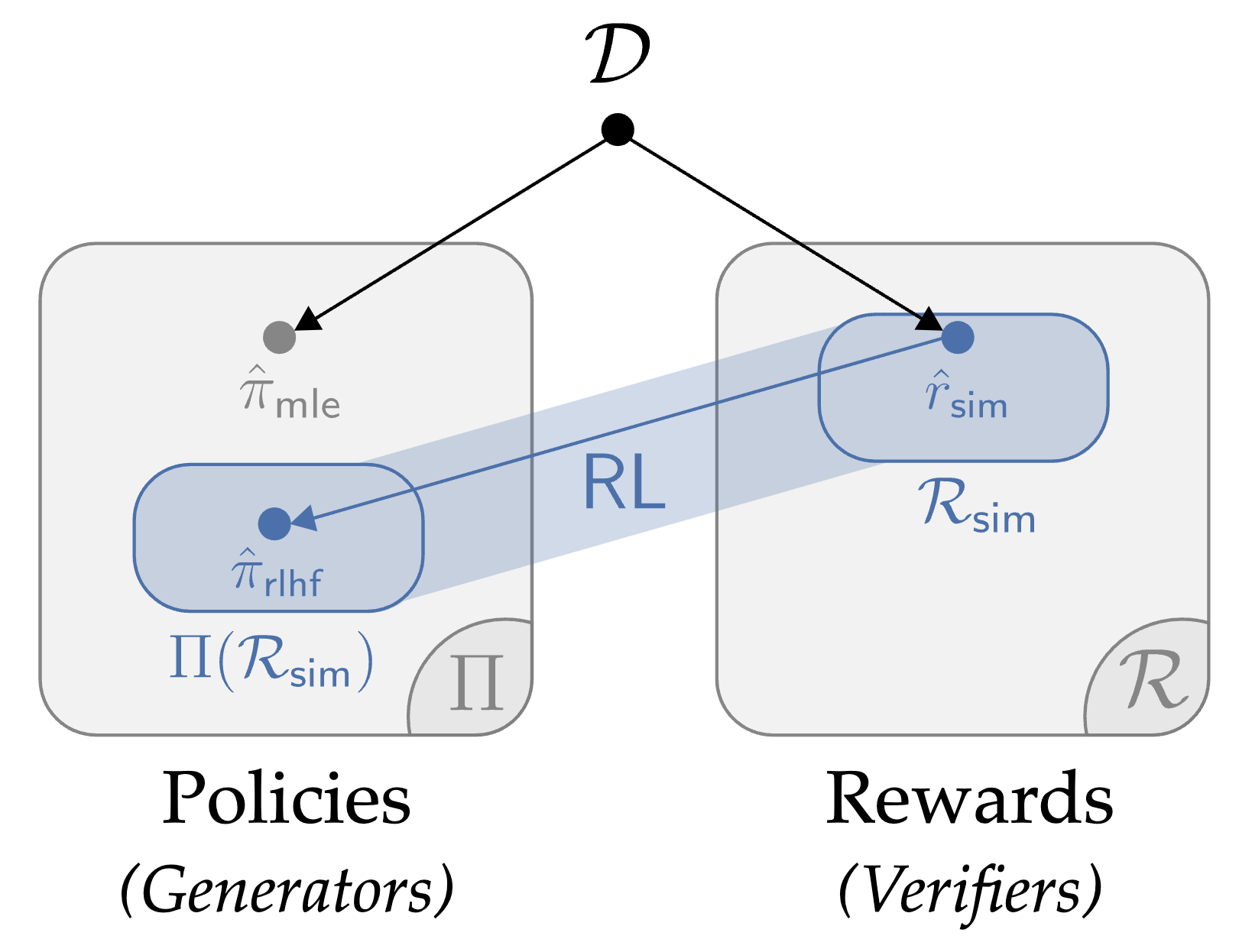
We explore how the value of RL in fine-tuning / RLHF seems to be fundamentally derived from generation-verification gaps. [Paper] [Talk]
SPO: Self-Play Preference Optimization
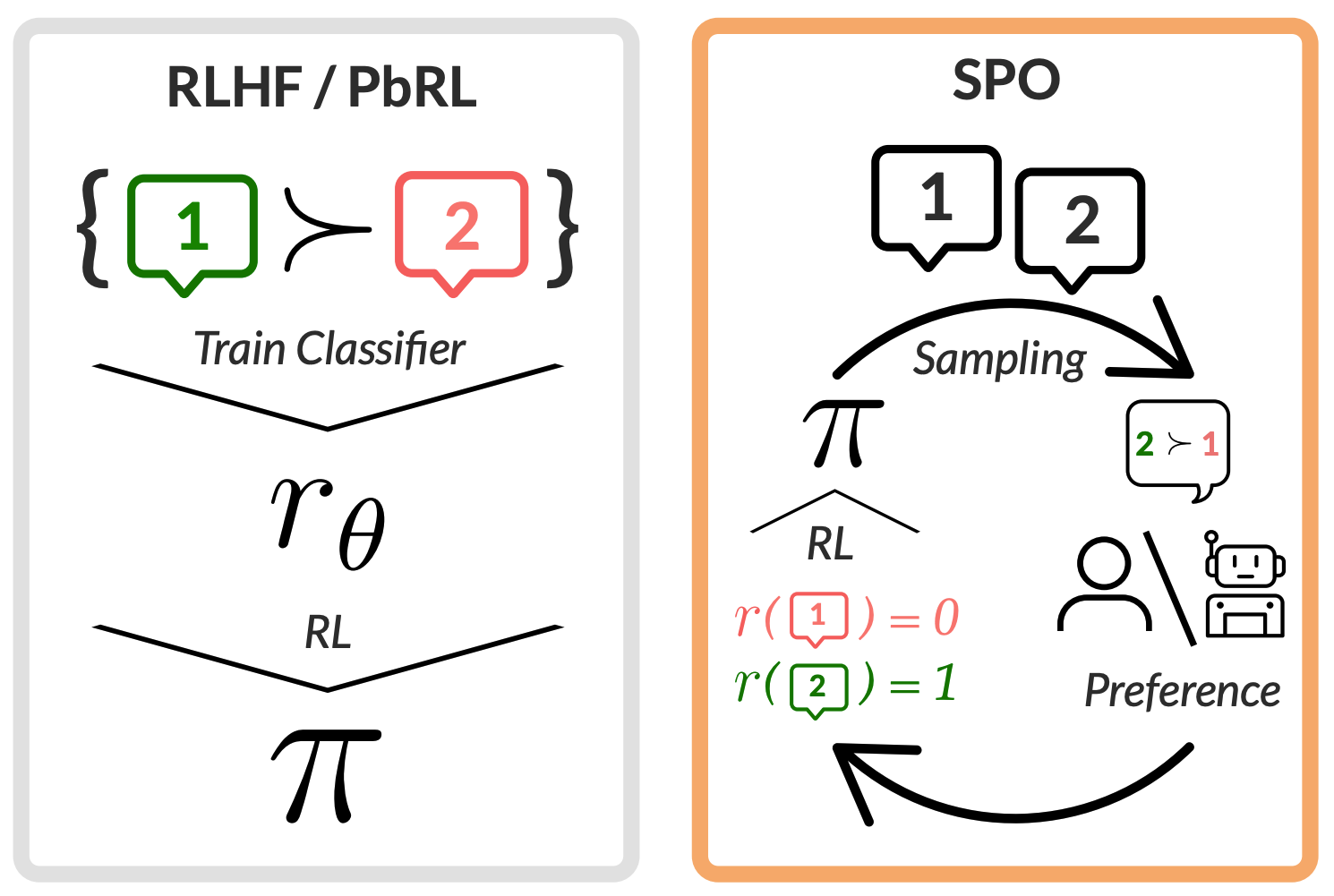
We derive a new fundamental algorithm for RLHF that robustly handles the complex, intransitive preferences that often result from aggregating a diversity of views. [Site] [Paper]
Inverse RL without RL
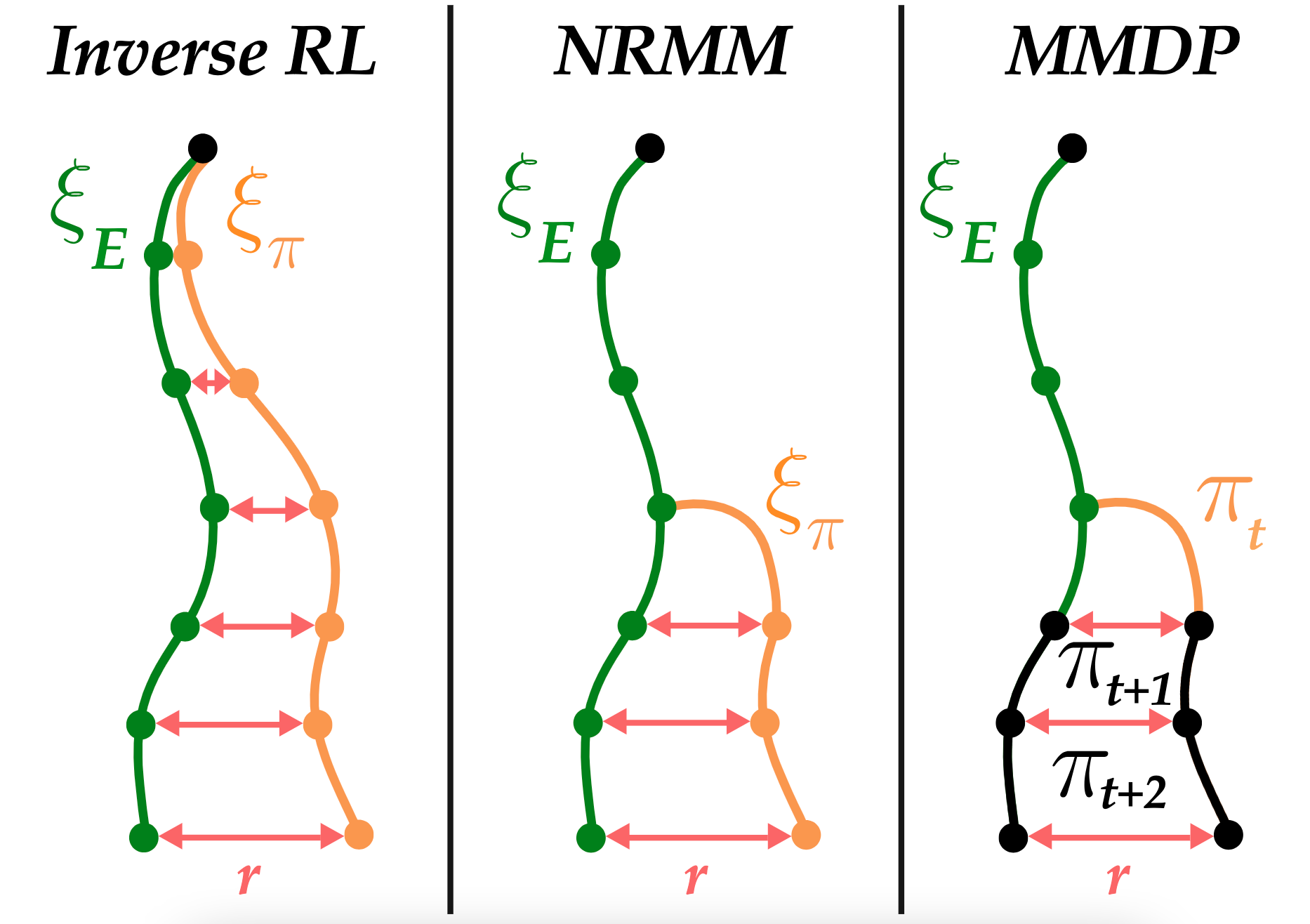
We derive exponentially faster algorithms for inverse RL by proving that local search is "all you need" for imitation. [Site] [Paper] [Podcast]
Of Moments and Matching
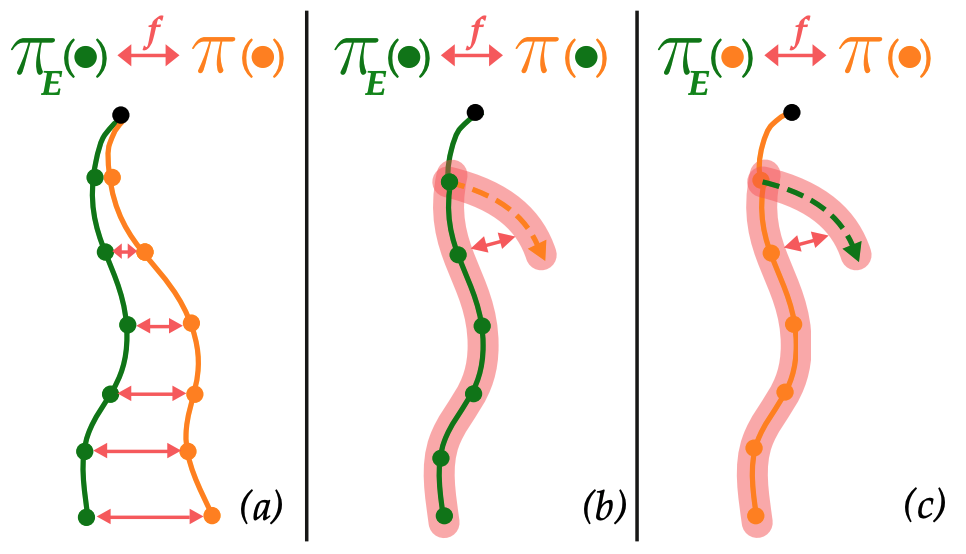
We provide a unifying, game-theoretic framework for imitation learning that explains when different algorithmic families can avoid compounding errors. [Site] [Paper] [Blog]